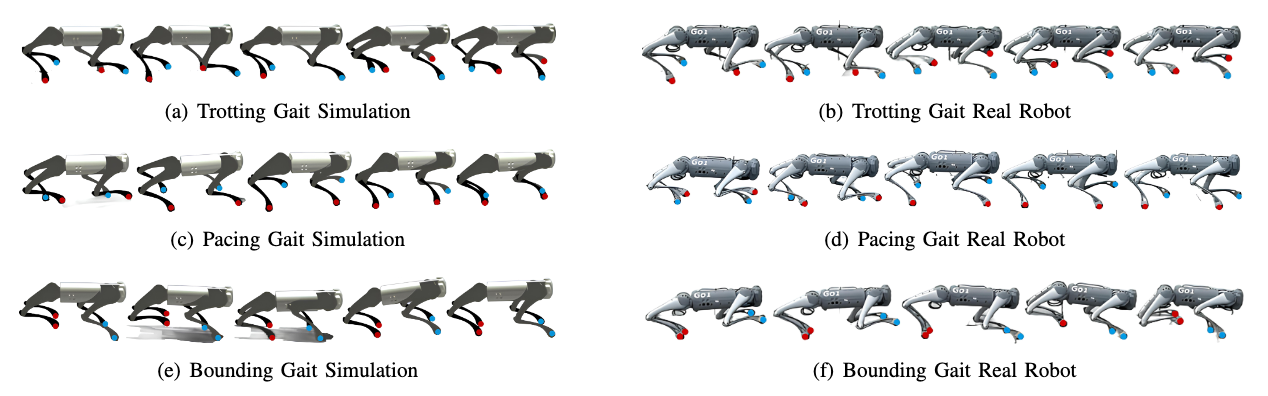
Diffusion models demonstrate superior performance in capturing complex distributions from large-scale datasets, providing a promising solution for quadrupedal locomotion control. However, the robustness of the diffusion planner is inherently dependent on the diversity of the pre-collected datasets. To mitigate this issue, we propose a two-stage learning framework to enhance the capability of the diffusion planner under limited dataset (reward-agnostic). Through the offline stage, the diffusion planner learns the joint distribution of state-action sequences from expert datasets without using reward labels. Subsequently, we perform the online interaction in the simulation environment based on the trained offline planner, which significantly diversified the original behavior and thus improves the robustness. Specifically, we propose a novel weak preference labeling method without the ground-truth reward or human preferences. The proposed method exhibits superior stability and velocity tracking accuracy in pacing, trotting, and bounding gait under different speeds and can perform a zero-shot transfer to the real Unitree Go1 robots.
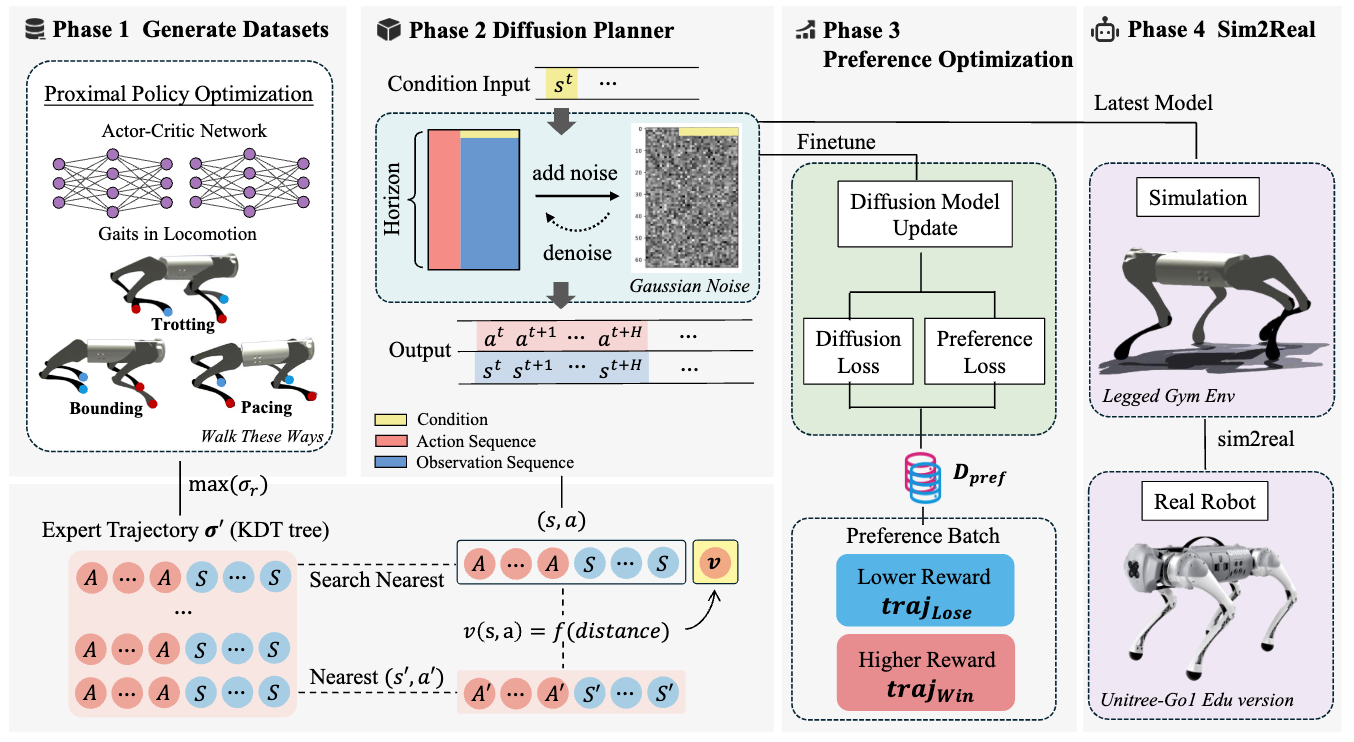
The overall illustration of the proposed framework. (1) Generate Datasets: the offline datasets among pacing, trotting, and bounding gait are collected through the expert PPO policy in the walk-these-ways task. (2) Behavior Cloning: given a condition input, the diffusion policy can produce a sequence of states and actions. (3) Preference Alignment: Conduct the preference alignment on the offline diffusion planner based on proposed weak preference labels. (4) Sim2Real: The refined policy is deployed on the Unitree Go1 robot.